 Docs
DocsConnect to DBMS as a data source using DBMS CLI tool
The DBMS CLI tool is the Process Intelligence Connector for database management system (DBMS) which allows submitting data from DBMS to Process Intelligence.
To submit data from DBMS to Process Intelligence:
-
Download the Process Intelligence Connector for DBMS from the ABBYY Help Center.
The Process Intelligence Connector ZIP file includes abbyy.timeline.dbms.client.jar. It is a command line tool that is able to submit data from DBMS to Process Intelligence.
- Configure the database as a data source in an Process Intelligence repository. For detailed instructions, see Configure the Process Intelligence repository.
- Run the Process Intelligence Connector for DBMS. For detailed instructions, see Run the connector for DBMS.
Configure the Process Intelligence repository
To enable Process Intelligence to receive and process data from DBMS:
- Open the Process Intelligence repository (click View > Repository).
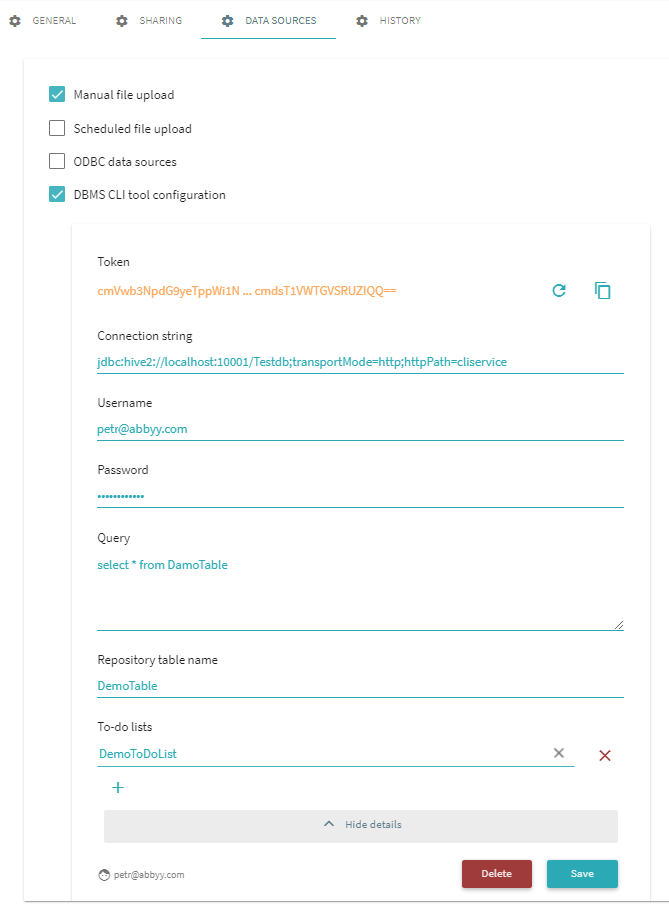
- Click Details > Data sources and select DBMS CLI tool configuration.
- Click Add configuration.
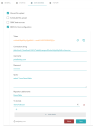
- In the opened dialog, complete the following fields:
- Connection string – A string that passed to a JDBC driver to initiate the connection with DBMS.
Examples:- Hortonworks Data Platform 2.6.5
Format: jdbc:hive2://<host>:<port>/<dbName>;<sessionConfs>?<hiveConfs>#<hiveVars>
Example: jdbc:hive2://localhost:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2
Driver can be downloaded here. - Apache Hive
Format: jdbc:hive2://<host>:<port>/<dbName>;<additionalparameters>
Example: jdbc:hive2://localhost:10001/Testdb;transportMode=http;httpPath=cliservice
Driver can be downloaded here. - Microsoft SQL Server
Format: jdbc:sqlserver://[serverName[\instanceName][:port]][;property=value[;property=value]]
Example: jdbc:sqlserver://10.21.8.11\SQLEXPRESS:1433;databaseName=DbWithBigData
ABBYY Timeline Connector for DBMS includes this driver. - Posgresql
Format: jdbc:postgresql://server-name:server-port/database-name
Example: jdbc:postgresql://localhost:5432/Testdb
ABBYY Timeline Connector for DBMS includes this driver.
- Hortonworks Data Platform 2.6.5
- Username – Specify the username for your DBMS account.
- Password – Specify the password for your DBMS account.
- Query – Specify a string of query to the DBMS to get data.
- Repository table name – Specify a name for table in the Process Intelligence repository. You can provide a new table name. During uploading, the data in a table is fully updated. Provide a new table name if you need to keep the data in an existing table.
- To-do list – You can specify an existing to-do list. To-do lists are lists of tasks that need to be performed after the data is filled into the table. For detailed instructions on configuring to-do lists, see Configure to-do lists.
- Connection string – A string that passed to a JDBC driver to initiate the connection with DBMS.
-
Click Save.
The connector token displays at the top.
Configure to-do lists
To create and configure a to-do list in the existing table of the repository:
- Click Tables in the Repository navigation menu and select the table for which you want to configure a to-do list.
-
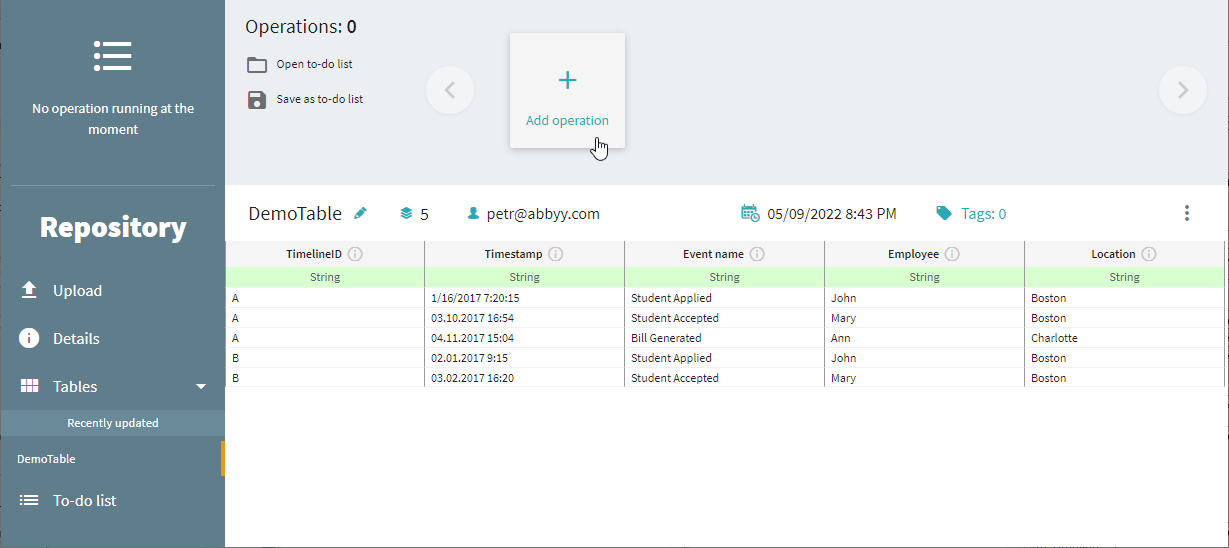
Click Add operation.
-
Select any operation you need to perform on the uploaded data.
If you need your data to be loaded both into the Process Intelligence repository and project to use the analysis tools, select Load into project. Select the project to load the data into and map Process Intelligence fields to table columns in the Edit Operation dialog.
Ensure that the names of the table columns obtained as a result of the SQL query match with the mapped columns in the table. Otherwise, the data cannot be loaded into the project.
- Click Save as to-do list.
Run the connector for DBMS
To start the connector, run the abbyy.timeline.dbms.client.jar file in the <Installation folder> using the commands below. <Installation folder> is the folder where the ZIP archive with the connector files had been extracted.
To connect to the Microsoft SQL Server or PostgreSQL, run the following command:
java -Dlog4j2.formatMsgNoLookups=true -jar abbyy.timeline.dbms.client.jar –ServerUrl <Server Url> --Token <Token> --AcceptEulaTo connect to the Apache Hive, run the following command:
java -Dlog4j2.formatMsgNoLookups=true -cp "*" abbyy.timeline.dbms.client.Program –ServerUrl <Server Url> --Token <Token> --DriverClassName <ClassName> --AcceptEulaThe JDBC driver must be in the same folder as the connector.
Where:
-
-Dlog4j2.formatMsgNoLookups=true – Option to prevent exposure to the CVE-2021-44228 vulnerability.
Add this option if you are using Apache Hive driver that bundles Log4j as a logging provider. The JVM flag -Dlog4j2.formatMsgNoLookups=true fixes the vulnerability. It has been implemented in log4j in the 2.10.0 version and later. If your Hive driver bundles a log4j version older than 2.10.0, you must update the driver.
-
Server URL – URL to the Process Intelligence server.
The forward slash character '/' cannot be used at the end of the Server URL. For example, https://my.timelinepi.com
-
Token– Token displayed on the Repository screen once the DBMS configuration has been added.
-
DriverClassName – Class name for external JDBC driver. That parameter is required for example for Hortonworks Data Platform 2.6.5.
-
AcceptEula – The End-User License Agreement (EULA) must be accepted before the connector starts. You can find the EULA in the connector’s folder: ./EULA.pdf.
When loading large tables, the connector sends data to Process Intelligence in parts of 10,000 rows each. After all the parts are fully uploaded, the data is displayed in the repository table.
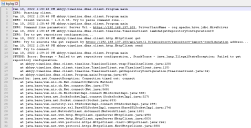
Example command to run the connector to upload data from Hortonworks Data Platform 2.6.5
java -Dlog4j2.formatMsgNoLookups=true -cp "*" abbyy.timeline.dbms.client.Program -s http://192.168.137.103 -t cmVwb3NpdG9yeTo2bWw2YVVzSTRnNkI2NkU2NGxzb3Y2WndrMlhSTTJ0YzhPR2RRektpa1MzMHNkWDdLQ2ZSODBZaE5zWV92eDk5Qm1DMF9YV3hLQ0pyRnlxN2Q2RUJvdw== -d org.apache.hive.jdbc.HiveDriver –AcceptEula
Generate a log file for the connector
By default, the connector outputs all information to the console. You can configure this information to be logged into a text file.
It is recommended that logging is configured when diagnosing problems and that unnecessary logging is removed if they are not actively being used. The log file can be useful when contacting technical support.
To configure logging, the Java Core Logging Facilities (java.util.logging) framework is recommended. To use the logger, add the following parameter to the command line when starting the connector:
-Djava.util.logging.config.file=logging.propertiesYou can then customize the logging configuration using the application programming interface (API) for the logger. For more information, see the java.util.logging package documentation.
Example
- Navigate to the folder where the abbyy.timeline.dbms.client.jar file is located. For example, C:\ABBYY\TimelineConnectorDBMS
-
Create a file named logging.properties with the following contents:
# Logger global settings
handlers=java.util.logging.FileHandler
.level=ALL
# File handler configuration
java.util.logging.FileHandler.level=INFO
java.util.logging.FileHandler.formatter=java.util.logging.SimpleFormatter
java.util.logging.FileHandler.limit=1000000
java.util.logging.FileHandler.pattern=log.log
java.util.logging.FileHandler.append=true
For detailed information about the FileHandler class and its properties, see the FileHandler documentation.
-
To use the logger, add the following parameter to the command line when starting the connector:
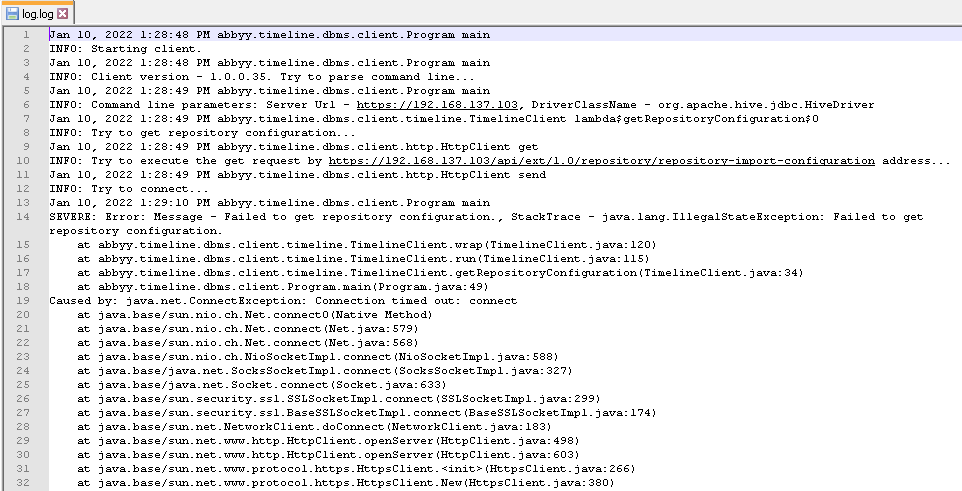
Copy-Djava.util.logging.config.file=logging.propertiesExample:
Copyjava -Djava.util.logging.config.file=logging.properties -Dlog4j2.formatMsgNoLookups=true -cp "*" abbyy.timeline.dbms.client.Program -s https://192.168.137.103 -t cmVwb3NpdG9yeTpENENzYy0ySkxpWWJzbTJDeWxILXlpMDBWLWp6Y3RNdEV3blJ0MHhQcTZERmlibU00ZGpWVHJFb0ZkekFFV1d4RHBaVWViZnhxdHNfWGVrMHVfSVFEdw== -d org.apache.hive.jdbc.HiveDriver -AcceptEula -
The log.log file will be written to the connector's folder where abbyy.timeline.dbms.client.jar file is located.