 Docs
DocsTraining classification models
This guide describes how to create and train classification models.
Classification models do not need to be created and trained if using a batch type with only one document type.
1. Create a training classification model
-
From the Admin Panel page, click Classification Models > Add classification model. For more information, see Classification models.
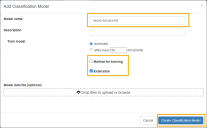
- Enter a name for the classification model.
-
Ensure the Marked for training check box is not selected.
This option must not be selected until all document batches have been pushed to Decipher IDP using the Blue Prism process. You will need to select this option at a later stage after the batches of training documents have been pushed to Decipher IDP.
- Enable the Extensible check box, if required. This allows additional document types to be included after the initial training model is configured.
- Click Create Classification Model.
2. Create document types
-
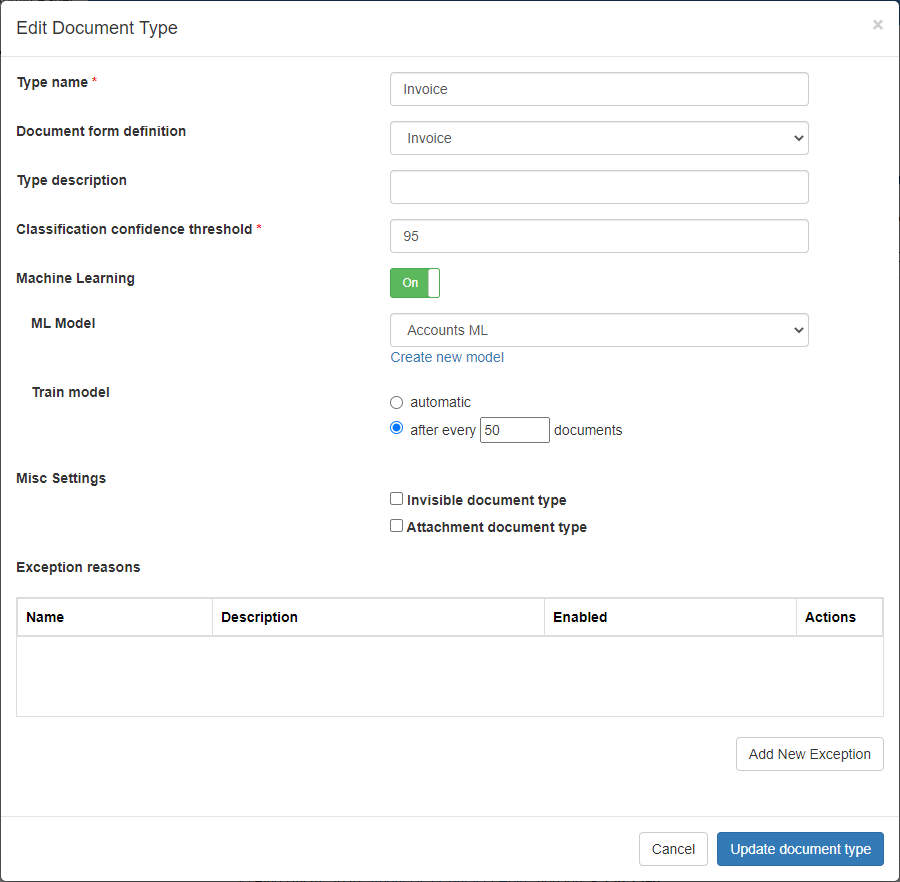
From the Admin Panel page, click Document Types > Add document type.
- Enter a name for the document type. The Document form definition (DFD) is not required at this stage.
- Click Update document type.
- Repeat to create all required document types.
3. Create a new batch type
-
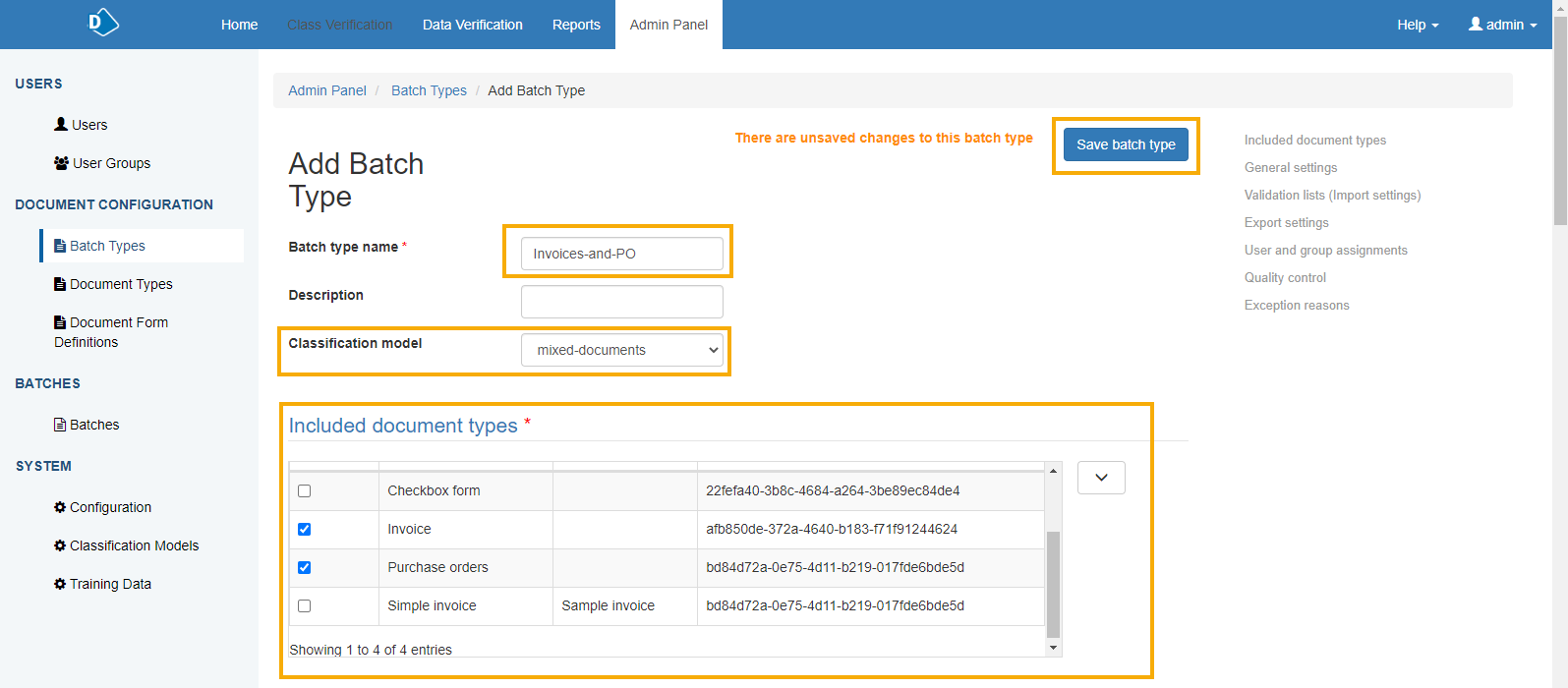
From the Admin Panel page, click Batch Types > Add batch type.

- Enter a name for the batch type.
- Select the new training classification model that you have just created.
- In the Included document types table, select the document types that you are including in this training batch.
- Enable the Perform Internal Document Separation check box. This option may cause multi-page documents to be split. For more information, see Troubleshooting.
- Click Save batch type.
4. Organize document types
-
Create folders for each document type that will be trained.
-
Add sample documents to each folder.
It is recommended that around 100 sample documents per document type are used, and that a similar number is used for each document type. A range of documents (with different file types, quality, number of pages, and from different sources) will provide the best results as this will help the model learn any variations in the document type.
Each document should only be used once per model, duplicate files will not effectively train the classification model.
5. Amend Blue Prism process
You now need to amend the Blue Prism Decipher - 01 Push Documents process (or your own process) to push a batch of training documents to Decipher.
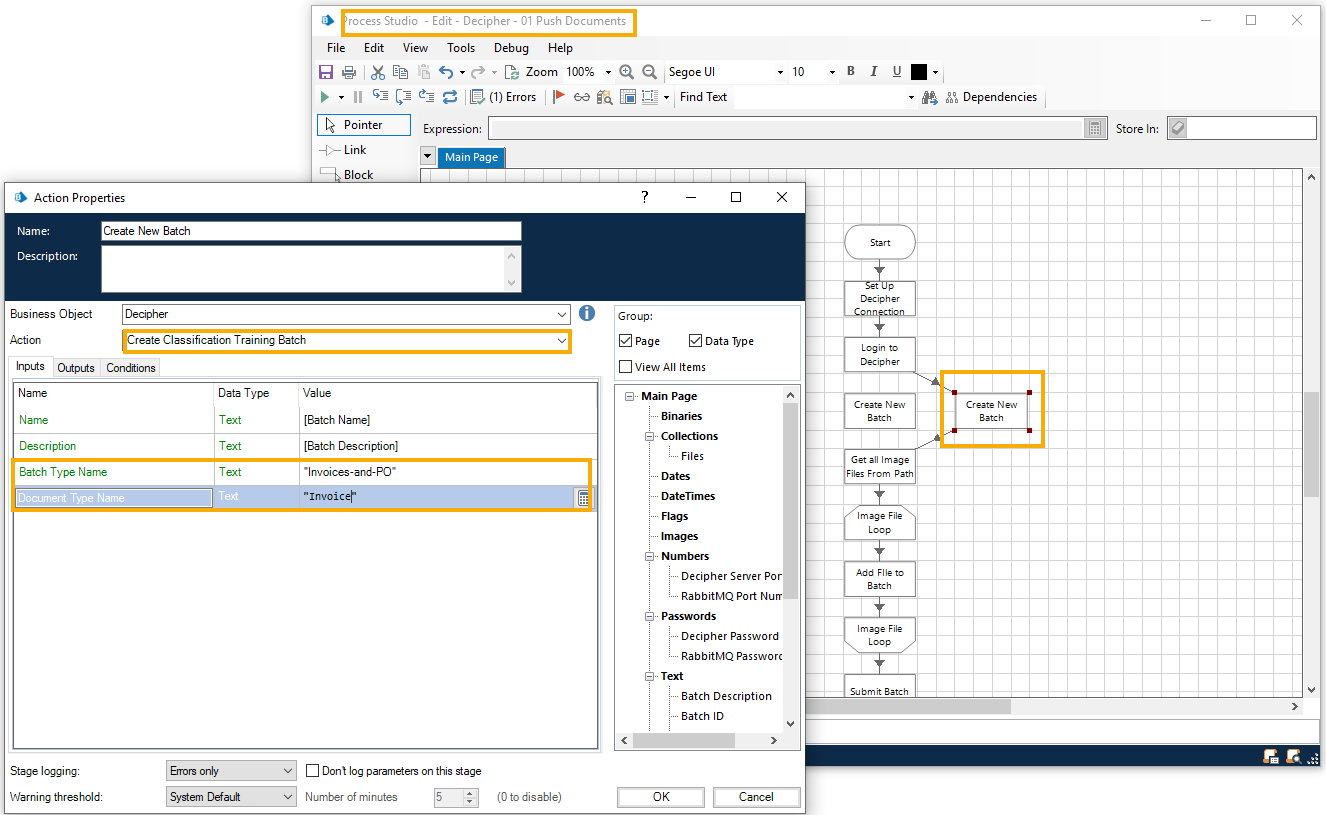
- Add a new Create New Batch action.
- In the Action Properties, select the Create Classification Training Batch action.
- In the Batch Type Name input field, enter the new batch type name.
-
Enter the document type of the first batch of documents you are sending for classification training.
- Ensure that the documents of the type entered are in the specified path and run the process to push the documents to Decipher IDP and train the classification model.
- Repeat this process using different document types, until all of the training documents have been pushed to Decipher IDP.
A minimum of two documents, grouped in the same or separate batches, are required to train the classification model. If the training model is configured to train after a specified number of documents, Decipher IDP requires the defined number of documents.
-
From the Admin Panel page, click Batches.
- Ensure all batches you processed have Waiting for Class Training in the Status column. This step is important if the Extensible option is not enabled for the classification model as no new document types can be added to the model after initial processing, even if the batches are at Image or OCR processing stages.
6. Update classification model
Once all of the training documents have been pushed to Decipher the classification model has been trained, batches pushed for classification have the status Waiting for Class Training.
- Edit the classification model, and select Marked for training.
- Click Update classification model.
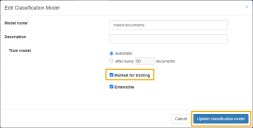
This triggers the training process, and batches now have the status In Class Training.
- To check the classification model training is complete, ensure all batches have the status Completed Class Training. This process can take some time depending on the number of documents, pages, document quality, and system architecture. Once complete, you can delete these batches and amend your process to use the Create Batch action to push documents for normal processing to Decipher IDP.
Your classification model is now trained and ready to be tested. If required, you can update the classification model to disable the Marked for training check box if you want to control when the model is next trained.
7. Load batch into class verification
-
From the Class Verification page, click Load Batch and load the batch of documents for verification.
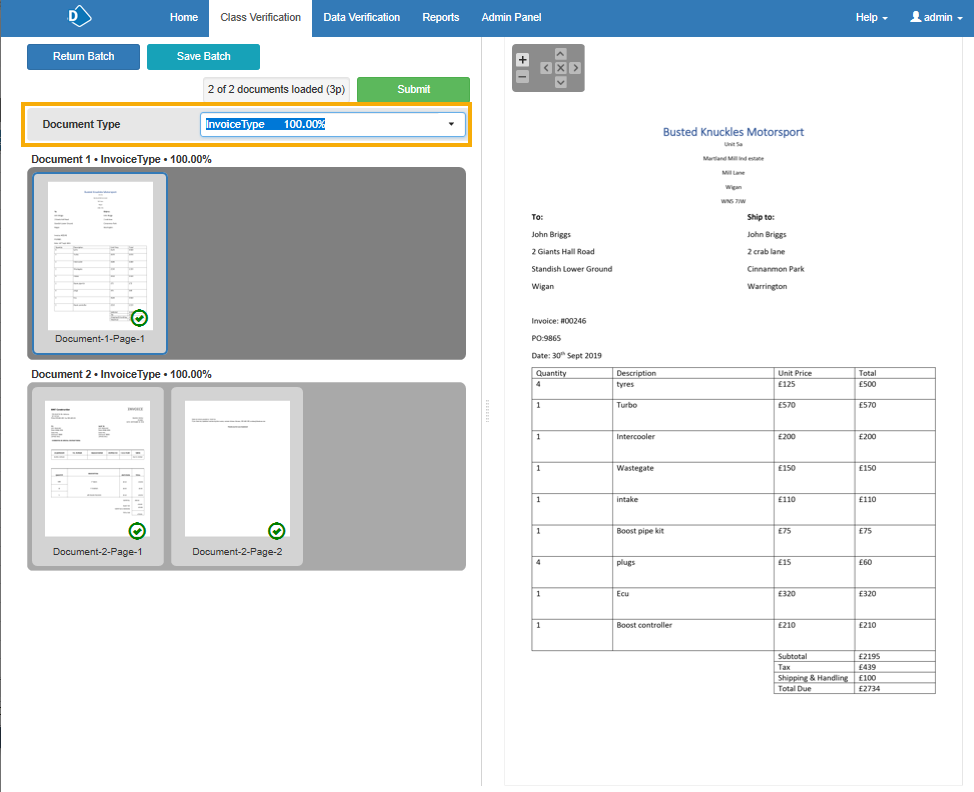
- The Document Type field displays the document type the classification model thinks this is and the level of confidence, as a percentage. The required level of confidence to pass class verification can be updated using the Classification confidence threshold setting on the document type. For more information see Document types.
- If the document type is incorrect, select the correct document type from the drop-down list and click Submit. If the document type is updated, this change is not saved to the classification model and will need to be manually corrected for future batches.
8. Skip class verification
When you are satisfied that the system is correctly classifying your documents, you can skip this process by disabling Class verify in Admin Panel > Configuration.
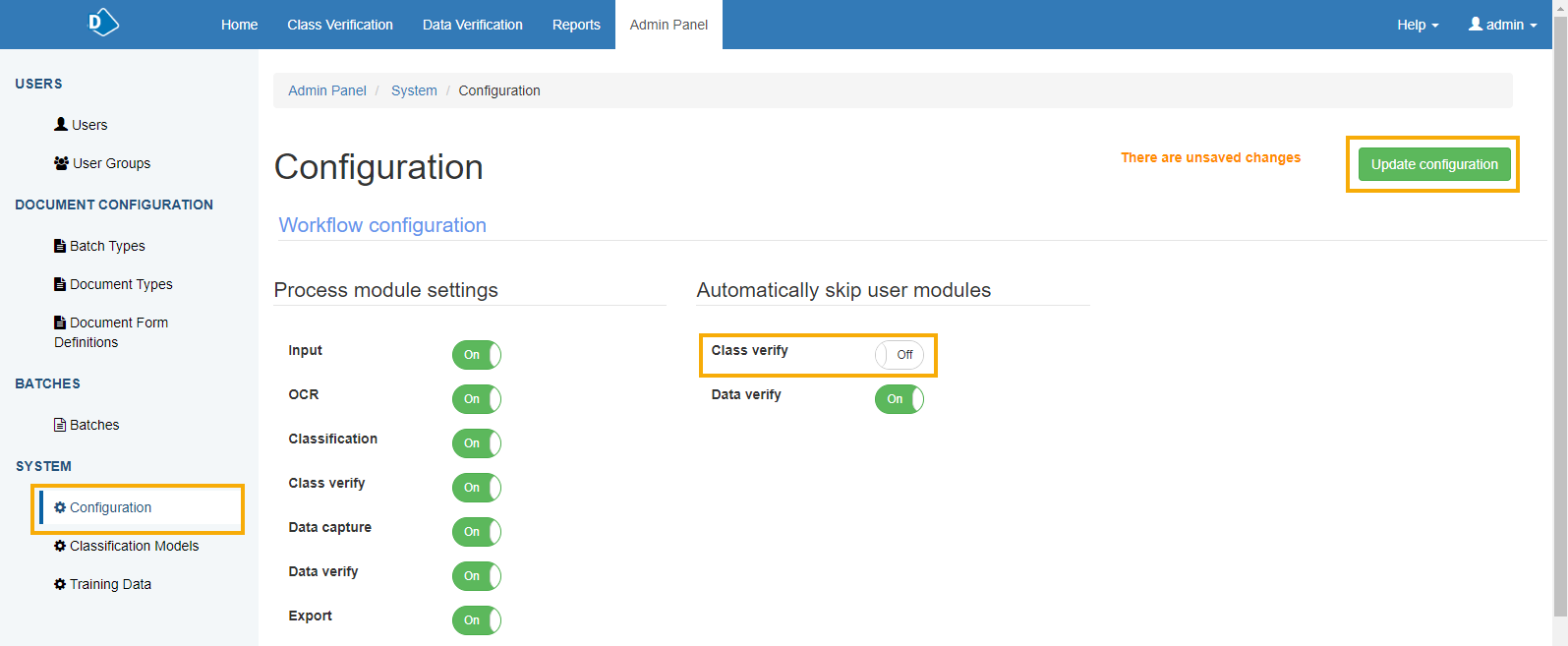
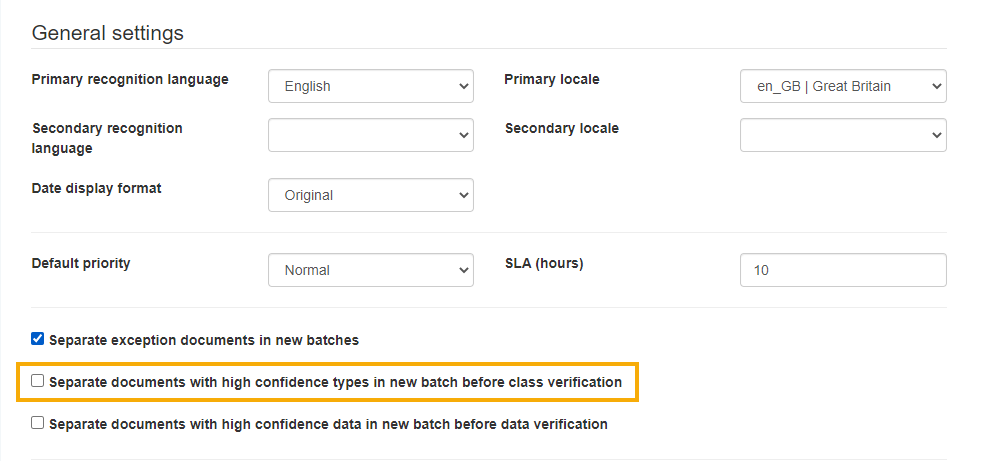
If you don’t want to skip class verification completely, you can edit the batch type under Admin Panel > Batch Types, and select Separate documents with high confidence types in new batch before class verification.
Updating Development classification models
To update a classification model in a Development environment, follow the process from step 4 above. Note that new document types cannot be added to classification models without the Extensible option being enabled.
Updating Production classification models
There are two methods for updating classification models in a Production environment:
-
Option A (manual) – A one-time manual update can be used if there is a selection of documents that require manual verification, and once updated, no further changes would be required.
-
Option B (automatic) – Automatic updates are useful if new document types regularly need to be added to the classification model. A process needs to be in place to upload such documents to Decipher IDP as new classification training batches.
If there are concerns that updating the classification model in Production could cause errors, it is recommended to first test the update in a Development environment before the changes are merged to Production.
Option A (manual)
To manually update the classification model:
-
Add the documents to folders for the respective document types. In addition, ensure the Production digital worker has the required access to the folder location.
-
Create a Blue Prism process to add classification training batches. It is recommended to configure the folder location, batch type name, and document type name as process input parameters.
-
Using this process in the Blue Prism Production environment, upload the relevant documents to the Decipher Production system as classification training batches. Ensure that each batch has at least two documents.
-
Update the classification model configuration to enable the Marked for training setting.
-
Once all the training batches have completed, update the classification model to disable the Marked for training setting.
-
Test and monitor the process using documents with the newly trained format, to ensure the update has been successful.
If the document confidence is still too low for auto-verification, it may be necessary to train further document samples by repeating this process.
Option B (automatic)
To automatically update the classification model:
-
Create a folder structure where new document samples can be added, with separate folders for each document type. Files can be added to these folders manually, or using a Blue Prism process. In addition, ensure the Production digital worker has the required access to the folder location.
-
Create a Blue Prism process to add classification training batches. It is recommended the process is configured to check there is at least two documents in a folder prior to uploading a new training batch.
-
Schedule the process in Production to run at regular intervals suitable for the expected number of new document samples.
-
Update the classification model in the Production environment to ensure the Marked for training setting is disabled, and to use the after every x documents option. This can be configured from 50 to 500, and it is recommended to use a document count that will find the appropriate balance between regular updates to ensure the model is up to date, but not result in overly frequent updates. Longer training sessions will consume the system's resources, and could impact the overall document processing performance. This value can be updated at any time.
-
Continually monitor the classification auto-verification performance, and consider manual updates where further action is required.
You can add a document count to the training batch name or description as a way of tracking how many documents are currently awaiting training.
Adding a new document type
For classification models that have the Extensible option enabled, new document types can be added to the model's training:
-
Create the new document type.
-
Update the existing batch type to include the new document type.
-
Create a folder for the document type and add sample documents.
-
Upload the sample documents in a classification training batch for the new document type.
-
Update the classification model configuration to enable the Marked for training setting.
To check the classification model training is complete, ensure all batches have the status Completed Class Training. This process can take some time depending on the number of documents, pages, document quality, and system architecture.
-
Once all the training batches have completed, update the classification model to disable the Marked for training setting.
Troubleshooting training classification models
Batches stuck at Waiting for Class Training status
-
Classification is not enabled in the Configuration page of the Admin panel. For more information, see Workflow configuration.
-
The Classification Client is not installed as part of the Automated Clients. For more information, see Install Decipher Automated Clients.
-
The training document count has not been met.
-
The batch type is not correctly configured to use the classification model.
Training batches is taking longer than expected
-
The batches may have a high volume of documents or pages, which takes longer to process.
-
The training batch only contains one document.
-
The document type is not in the existing classification model, and the model is not configured with the Extensible option enabled.
Documents are not correctly recognized
-
Not enough documents were used during training.
-
The document types are too similar.
-
The document was not used during training.
-
The document quality is too low.
-
Only PDF files with vector data were used during training, leading to other data types (such as scanned data) not being recognized. Ensure sample documents contain a range of document types.
Attachments are not correctly recognized
-
Document Split Mode input, which is part of the Decipher VBO's Create Batch action, must be configured to 1 to enable document splitting. For more information, see Using the Decipher VBO.
Alternatively, enable the Perform internal document separation option for the batch type. If this option is enabled, multi-page documents will be split into separate files. For more information, see Batch types.
-
Additional classification model training is required.
Multi-page documents are being split into single documents
-
Document Split Mode input, which is part of the Decipher VBO's Create Batch action, must be configured to 3 to prevent document splitting. For more information, see Using the Decipher VBO. In addition, ensure the Perform internal document separation option for the batch type is disabled. For more information, see Batch types. This combination of the two settings means that files will not be split or merged.
-
Additional classification model training is required.
