 Docs
DocsOptical Character Recognition (OCR, Texterkennung)
Blue Prism bietet verschiedene OCR-Funktionen für Bildschirmtext:
Native Zeichenerkennung
Oberflächenautomatisierung verwenden
Wenn der Blue Prism Anwendungsmodellierer nicht direkt verwendet werden kann, um Anwendungselemente zu identifizieren, kann eine Technik namens Oberflächenautomatisierung genutzt werden, um ein Bild des Anwendungsfensters zu erfassen und die Position von Schlüsselelementen darauf zuzuordnen. Solche Anwendungen können mithilfe von Bildschirmbereichen, Bildabgleichen und Zeichenerkennung modelliert werden. Diese Technik ist nützlich, um Anwendungen zu erfassen, die nicht auf demselben Computer wie Blue Prism Enterprise ausgeführt werden und für die keine anderen Erfassungsmodi verfügbar sind.
Die native Zeichenerkennung, die auf dem Schriftartenabgleich basiert, wird über die Aktion „Texterkennung“ in einer Lesephase genutzt, wenn sie für einen zuvor erfassten Anwendungsmodelliererbereich verwendet wird. Dadurch werden Textdaten aus dem Bereich extrahiert und in einem Datenelement gespeichert. Die Eingabeparameter für die Aktion Texterkennung sind Schriftart, Vordergrundfarbe und Hintergrundfarbe.
Für die native Zeichenerkennung muss die Schriftart vor der Verwendung generiert werden. Weitere Details finden Sie unter Schriftarten.
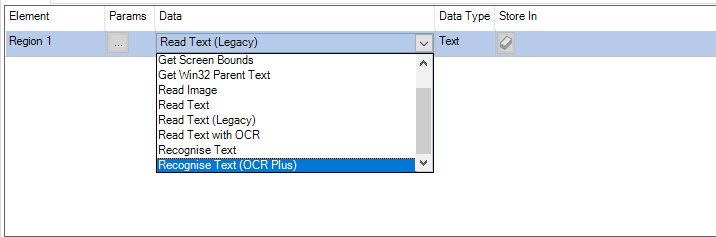
OCR Plus verwenden
OCR Plus bietet eine verbesserte Zeichenerkennung mit höherer Genauigkeit und Zuverlässigkeit durch:
-
Automatische Identifizierung von Vordergrund- und Hintergrundfarben.
-
Unterscheidung zwischen scheinbar identischen Zeichen (wie dem Buchstaben O und der Zahl 0) und Klärung durch RegEx-Muster (reguläre Ausdrücke).
-
Verbesserung des Algorithmus für den Schriftartenabgleich.
Dies wird über die Aktion Text erkennen (OCR Plus) in einer Lesephase genutzt. Die Eingabeparameter sind Schriftart und optional RegEx. Auch wenn keine Eingabeparameter angegeben sind, erkennt das System die Schriftart und versucht, das Wort so genau wie möglich abzugleichen. Wenn jedoch Unklarheiten bestehen, wird ein standardmäßiger regulärer Ausdruck verwendet, der eines der folgenden Wortmuster akzeptiert:
- Großbuchstaben, dann Kleinbuchstaben
- Großbuchstaben oder nur Kleinbuchstaben
- Nur Zahlen
Beispiele für typische reguläre Ausdrücke:
- Zahl: „[0-9]+“
- Wort aus Großbuchstaben, dann Kleinbuchstaben: „[A-Z][a-z]*“
- Zeichenfolge aus Großbuchstaben und Zahlen: „[0-9A-Z]+“
Tesseract OCR
In Situationen, in denen es nicht angemessen ist, die native Engine zur Zeichenerkennung zu verwenden, um mit Bildschirmtext zu interagieren, z. B. wenn geglätteter Text erzwungen wird oder mit gescannten oder anderweitig eingeschränkten Kopien elektronischer Dokumente interagiert wird, kann Blue Prism eine eingebettete Tesseract OCR-Engine verwenden, um Text mithilfe einer Mustererkennung und komplexen, sprachbasierten Texterkennung zu erfassen.
Für maximale Effektivität der Texterkennung ist eine Auflösung von mindestens 300 dpi (dots per inch) erforderlich. Bei Bildern wie Bildschirmtext mit einem niedrigeren dpi-Wert vergrößert ein Skalierungsparameter künstlich den erfassten Ausschnitt, bevor er an die Engine weitergegeben wird. Ein Skalierungsfaktor von 4 oder 5 liefert meist gute Ergebnisse.
Die Tesseract OCR-Engine wird über die Aktion Lesen des Textes mit OCR in einer Lesephase bei der Verwendung mit einem zuvor erfassten Anwendungsmodelliererbereich genutzt und bietet Optionen, um Text, Listen und Raster auszulesen. Die vorbereiteten Bilder können auch an spezifische Diagnoseverzeichnisse gesendet werden, um sicherzustellen, dass die angewandte Skalierung für den ausgewählten Bereich ausreicht.
Sprachpakete
Sprachpakete für Tesseract sind online erhältlich. Blue Prism ist mit Tesseract 4.0.0 kompatibel und es muss darauf geachtet werden, die richtige Hauptversion der Sprachdateien zu verwenden. Die Sprachdateien für Version 4.0.0 können derzeit auf der Website von Tesseract heruntergeladen werden.
Um andere Sprachen zu verwenden, laden Sie die entsprechenden Dateien in den Ordner „Tesseract\tessdata“ herunter (meist C:\Programme\Blue Prism Limited\Blue Prism Automate\Tesseract\tessdata).
Die Sprachdateien sind durch ein Präfix mit dem Sprachcode gekennzeichnet, z. B. deu (Deutsch), fra (Französisch), jpn (Japanisch), chi-tra (traditionelles Chinesisch). Nach der Installation auf allen erforderlichen Geräten kann dieser Code im Sprachparameter der Aktion Lesen des Textes mit OCR in einer Lesephase angegeben werden, damit die Engine das gewünschte Sprachpaket verwendet.
Seitensegmentierungsmodus
Die Aktion Lesen des Textes mit OCR in einer Lesephase verfügt über den optionalen Textparameter „Seitensegmentierungsmodus“, durch den ein von Tesseract definierter Wert angegeben werden kann. Die Werte, die in diesen Parameter eingegeben werden können, werden zusammen mit einer Kurzbeschreibung ihrer Aktion im Folgenden gezeigt.
Wird kein Wert für den Seitensegmentierungsmodus angegeben, wird der Standardwert „Auto“ verwendet.
|
Parameter |
Beschreibung |
|---|---|
|
OSD |
Nur „Orientation and Script Detection“ (OSD) |
|
AutoWithOSD |
Automatische Seitensegmentierung mit OSD |
|
AutoNoOCR |
Automatische Seitensegmentierung, aber ohne OSD oder OCR |
|
Auto |
Vollautomatische Seitensegmentierung, aber ohne OSD (Standard) |
|
Column |
Erwartet eine einzelne Textspalte variabler Größe |
|
VerticalBlock |
Erwartet einen einzigen einheitlichen vertikal ausgerichteten Textblock |
|
Block |
Erwartet einen einzigen einheitlichen Textblock |
|
Line |
Behandelt das Bild als einzelne Textzeile |
|
Word |
Behandelt das Bild als einzelnes Wort |
|
CircledWord |
Behandelt das Bild als einzelnes Wort in einem Kreis |
|
Character |
Behandelt das Bild als einzelnes Zeichen |
|
SparseText |
Findet möglichst viel Text in keiner bestimmten Reihenfolge |
|
SparseTextWithOSD |
Wenig Text mit OSD |
|
RawLine |
Behandelt Bild als einzelne Textzeile, um Tesseract-spezifische Workarounds zu umgehen. |
Weitere Informationen zu Segmentierungsmodi finden Sie in der offiziellen Dokumentation auf der Website von Tesseract.
