 Docs
DocsLes passerelles de données
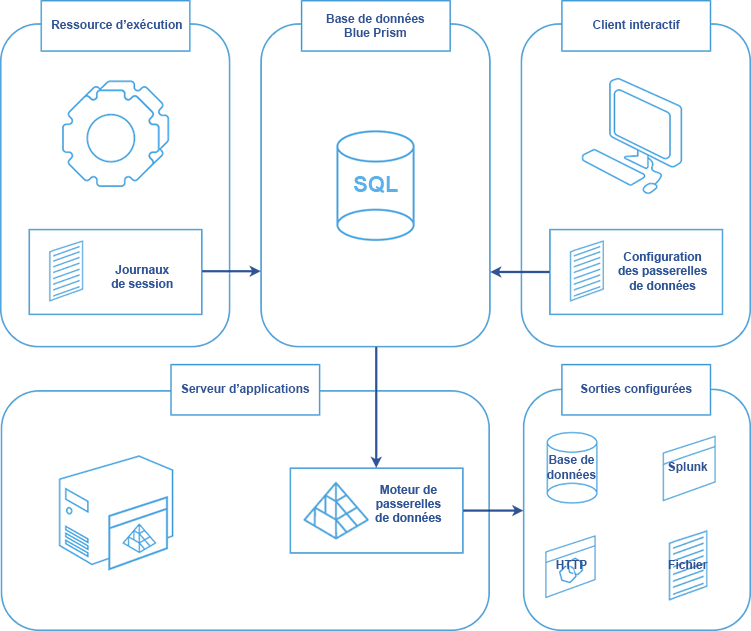
Les passerelles de données offrent une méthode centralisée et facile à employer pour extraire des données de Blue Prism et les utiliser dans des systèmes externes de surveillance et de rapports, de stockage de données à long terme et d’alimentation des modèles d’apprentissage automatique. Les méthodes de configuration avancée permettent de rediriger les données vers toute cible requise. Les données peuvent être visualisées et analysées pour fournir des informations précieuses sur les environnements Blue Prism sans avoir à construire manuellement des capacités similaires dans chacune des automatisations de processus concernées.
En se dotant de la capacité à stocker des données en dehors de la base de données Blue Prism, les organisations peuvent utiliser les passerelles de données pour répondre à des besoins de stockage de données flexibles. Par exemple, une organisation pourrait vouloir sauvegarder toutes ses données de session en dehors de la base de données Blue Prism ou elle pourrait choisir de stocker les données dans la base de données pour une période plus courte, en produisant une copie de ces données pour un stockage de données à plus long terme.
Des réglages sont appliqués pour déterminer quelles données seront traitées par le moteur de passerelles de données et une configuration définit les sorties vers lesquelles les données seront envoyées. Les données provenant des journaux de session, des tableaux de bord publiés, des étapes de processus et de l'analyse de la file d'attente des tâches peuvent être envoyées vers une multitude de sorties externes : points de terminaison HTTP, bases de données externes, outils d’analyse tiers et fichiers plats, offrant une flexibilité et un contrôle sur l’analytique et le stockage des données.
Le moteur de passerelles de données utilise un certain nombre de composants Logstash pour envoyer les données de journal de session vers les sorties configurées.