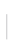 Docs
DocsClassification models
Classification models enable Decipher IDP to use training data to automatically classify your documents. You can create more than one classification model, where each model is responsible for classifying several types of documents. For example, you can have one model, which classifies invoices and purchase orders, and another model for classifying job applications and ID cards.
For more information on the classification training process, see Training classification models.
Create a classification model
To create a new classification model, or edit an existing one:
-
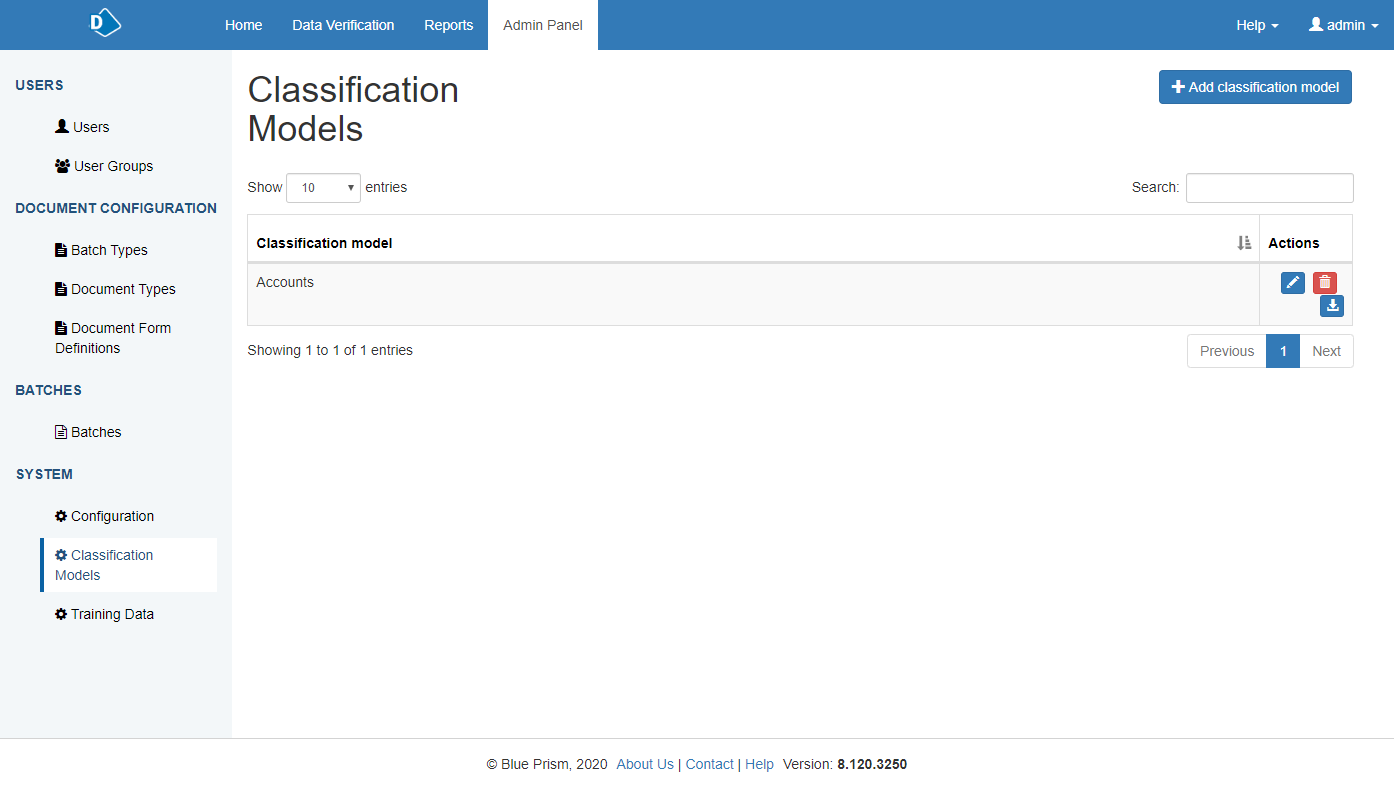
Click Admin Panel > Classification Models > Add classification model to add a new model. Or you can edit an existing model.
-
Complete the following fields:
Model name
Enter a meaningful name for this model, such as the category of documents this model will be trained to recognize, such as Accounts.
Description
Enter a description of the model.
Train model
Determine how the classification model will be trained. This can be set to:
-
automatic – The model will update after every 30,000 documents, or every 90,000 pages, whichever is reached first. This is recommended if there is a high number of document types, or if there is a high variance in appearance between documents of the same type.
-
after every X document – The model is trained after the specified document count, which can be set from 50 to 500. The default is every 50 documents. This is recommended where training documents are regularly uploaded, and the model is required to automatically update. The document count is cumulative for all training batches, and not separated per document type.
Disabled
Select this option to disable both the training options, automatic and after every X document. This is recommended when training documents are regularly uploaded, but you want to control when the model is updated.
Marked for training
Select this option to immediately update the model, subject to system speed and availability, using batches that are awaiting training. Enabling this option will allow all newly uploaded training batches to be processed as soon as they are ready. This option is not affected by the Disabled setting and will continue to train the model.
When training a classification model this option must not be selected until all document batches have been pushed to Decipher IDP using the Blue Prism process. You will then need to select this option after the batches have been pushed to Decipher IDP and before class verification.
Extensible
Select this option if you want the classification model to be extensible (can be extended). This option allows new document types to be added to the model after the initial training. This is recommended when training samples are not available at the time of the initial model training, for one or more of the document types. Alternatively, this can be selected if there is a chance of a new document type being added to the model at a later date.
An extensible model takes up more space on the server as it stores the original encrypted model data (images not included). A non-extensible model cannot be extended with additional document types and will therefore be smaller in size.
If the Extensible option is enabled on an existing model, the training will be restarted when the next training batch is processed. All previous training will be lost.
Model data file
Drag an existing classification model, a CMO file, if required.
-